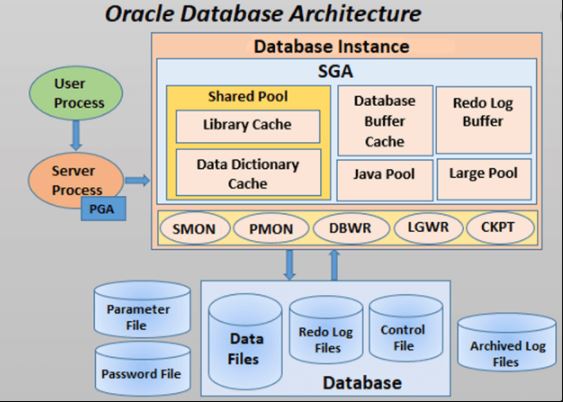
What is redo logs?
In Oracle, the term "redo log" refers to a critical component of the database system that helps ensure data durability and recoverability. The redo log consists of a set of files, known as redo log files or redo logs, which store a record of changes made to the database.
Whenever a transaction modifies data in the database, Oracle generates redo entries, also known as redo records, that capture the before and after images of the modified data. These redo records are written to the redo log files in a sequential manner. The redo log files provide a means to recover the database to a consistent state in the event of a system failure or a database crash.
Redo logs serve two primary purposes:
1. Recovery: The redo log files are crucial for database recovery operations. In case of a failure, Oracle can use the redo log files to reapply the changes made by committed transactions that were not yet written to the data files, thus ensuring data consistency and integrity.
2. Redo Generation: The redo log files also play a role in maintaining the durability of the database. As changes are made to the database, the redo log files capture these modifications, allowing Oracle to recreate or "redo" those changes if necessary.
In summary, the redo log in Oracle is a fundamental component that helps ensure data integrity and recoverability by storing a record of changes made to the database. It plays a crucial role in database recovery and provides durability by capturing redo entries for all modifications made to the database.
Find Redo Log Size
To find the size of the redo log in Oracle, you can query the database dictionary views. Specifically, you can retrieve the redo log size information from the `V$LOG` view. Here's an example query:

This query will return the group number (`GROUP#`), thread number (`THREAD#`), and size in bytes (`BYTES`) of each redo log group in the database.
Note that the `V$LOG` view provides information about individual redo log groups, and the size of the redo log is typically the sum of the sizes of all the groups. So, if you want to calculate the total size of the redo log, you can use the following query:

This query will give you the total size of the redo log in bytes. You can divide the result by an appropriate unit (e.g., 1024 for kilobytes, 1024*1024 for megabytes) to obtain the size in a more readable format.
Keep in mind that the size of the redo log can vary depending on the configuration and settings of your Oracle database.
Redo Log Switch Frequency
To determine the redo log switch frequency in Oracle, you can query the database dictionary views to gather information about the redo log switches. Redo log switches occur when a filled redo log file is switched with an empty one to ensure continuous logging of database changes. Here's an example query:

This query retrieves the count of redo log switches from the `V$LOG_HISTORY` view. The `V$LOG_HISTORY` view provides a historical record of redo log switches that have occurred in the database.
You can also calculate the redo log switch frequency over a specific period of time by considering the timestamps of the redo log switches. Here's an example query that calculates the average redo log switch frequency per day:

This query divides the count of redo log switches by the time difference between the earliest and latest redo log switch timestamps to obtain the average frequency per day.
Note that the `V$LOG_HISTORY` view retains historical information for a limited period, which is determined by the database configuration. Therefore, if you need to analyze redo log switch frequency over a longer duration, you might need to consider other methods, such as log file monitoring tools or auditing features provided by Oracle or third-party tools.
Redo Log Location in Oracle
In Oracle, the redo log files are typically stored in a specific directory known as the "log file directory" or "log file location." The exact location of the redo log files depends on the configuration of the database and the operating system.
To find the location of the redo log files, you can query the `V$LOGFILE` view, which provides information about the redo log file configuration. Here's an example query:

This query retrieves the file paths (`MEMBER`) of the redo log files in the database. The `V$LOGFILE` view contains information about the redo log file members, including their locations.
Each redo log file member has a specific path associated with it. The path can be an absolute file system path or a relative path within the database directory structure, depending on the configuration. By querying the `V$LOGFILE` view, you can obtain the exact location of each redo log file member.
Additionally, you can also check the Oracle initialization parameter file (usually called "init.ora" or "spfile.ora") to find the specific location of the redo log files. Look for the parameter `LOG_FILE_NAME_n`, where `n` represents the redo log group number. The parameter value will indicate the path and filename of each redo log file member.
Remember to adjust the query or examine the parameter values for all redo log groups in case there are multiple groups configured in your Oracle database.
Redo Log File Status Descriptions
UNUSED – Online redo log has never been written to. This is the state of a redo log that was just added, or just after a RESETLOGS, when it is not the current redo log.
CURRENT – Current redo log. This implies that the redo log is active. The redo log could be open or closed.
ACTIVE – Log is active but is not the current log. It is needed for crash recovery. It may be in use for block recovery. It may or may not be archived.
CLEARING – Log is being re-created as an empty log after an ALTER DATABASE CLEAR LOGFILE statement. After the log is cleared, the status changes to UNUSED.
CLEARING_CURRENT – Current log is being cleared of a closed thread. The log can stay in this status if there is some failure in the switch such as an I/O error writing the new log header.
INACTIVE – Log is no longer needed for instance recovery. It may be in use for media recovery. It might or might not be archived.